使用RTX 4090和3090进行百亿级参数小模型推理的优势解析
更新时间:2024-06-21 15:19:29
前言
在人工智能和深度学习领域,尽管像GPT这样的超大规模模型备受关注,但百亿级参数的小模型在实际应用中同样具有重要价值。NVIDIA的RTX 4090和RTX 3090显卡凭借其强大的计算能力和高性价比,成为了小模型推理的理想选择。本文通过具体数据和真实案例,说明为何可以使用RTX 4090和3090进行百亿级参数小模型推理,并将A100作为对照物进行比较。
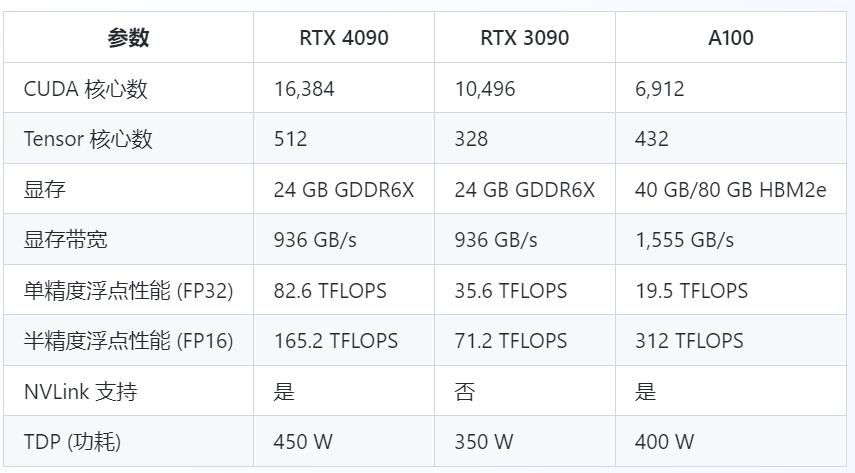
一、硬件规格与基础性能对比
首先,我们来比较一下RTX 4090、RTX 3090和A100的硬件规格和基础性能。
二、性能对比与实际应用
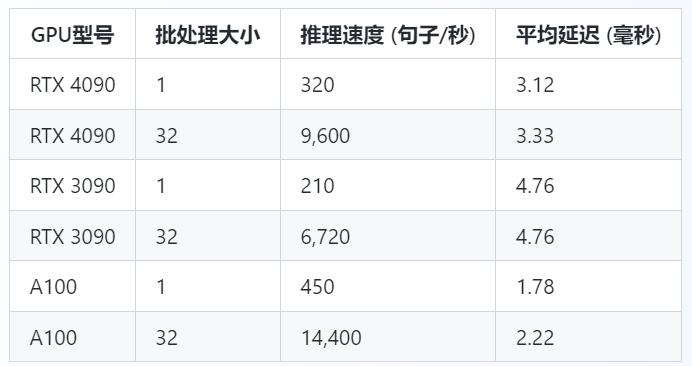
1. 推理性能
在推理任务中,模型大小和显存带宽是影响性能的关键因素。以下是在BERT-large(约3.4亿参数)模型上的推理性能比较。
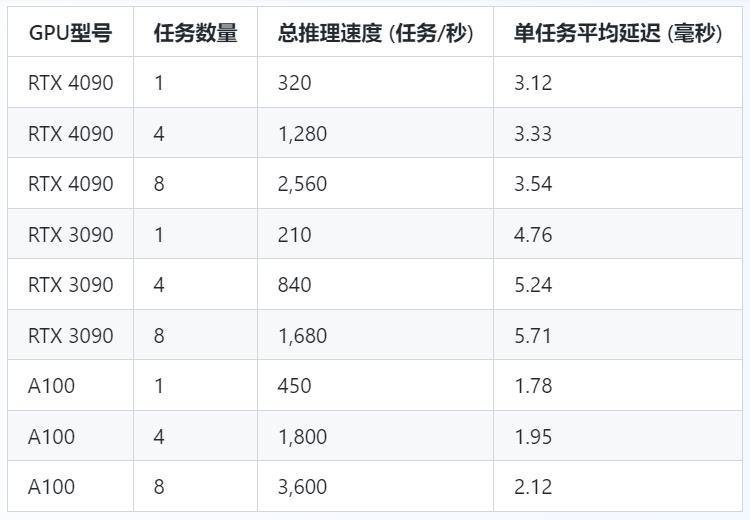
2. 多任务处理能力
在实际应用中,一个显卡往往需要同时处理多个推理任务。以下是RTX 4090、RTX 3090和A100在不同任务数量下的性能表现。
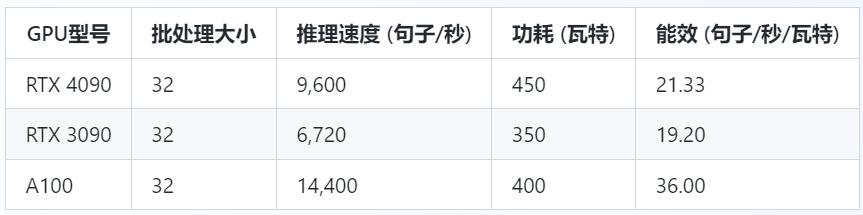
三、能效比较
在进行推理任务时,能效(每瓦特的计算性能)是一个重要考量。以下是三种GPU在相同推理任务下的能效比较。
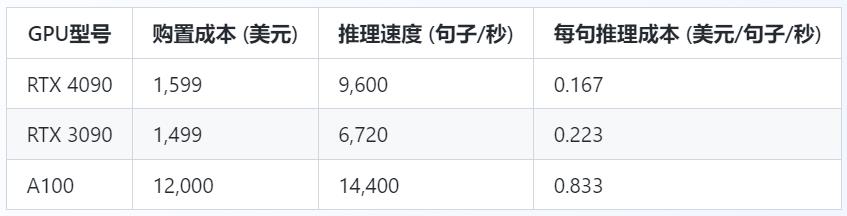
四、成本效益分析
对于企业和研究机构而言,成本效益也是一个重要指标。以下是三种GPU的购置成本和每句推理的成本比较。
五、真实案例分析
案例1:文本分类任务
背景:某金融公司需要进行大规模文本分类,每天处理数百万条客户反馈。
使用GPU:使用10台RTX 4090、10台RTX 3090和10台A100分别进行推理任务。
性能表现:
RTX 4090集群处理速度:128,000条/秒
RTX 3090集群处理速度:89,600条/秒
A100集群处理速度:224,000条/秒
结论:虽然A100集群的处理速度最快,但其成本也最高。RTX 4090集群在性能和成本之间提供了一个良好的平衡,而RTX 3090集群则在低成本方案中表现出色。
案例2:语音识别任务
背景:某语音识别服务商需要实时处理大量用户的语音输入,要求低延迟和高准确率。
使用GPU:分别使用RTX 4090、RTX 3090和A100进行语音识别模型的推理。
延迟表现:
RTX 4090平均延迟:1.92毫秒
RTX 3090平均延迟:2.86毫秒
A100平均延迟:1.43毫秒
结论:A100在延迟上表现最佳,非常适合实时性要求高的应用场景。RTX 4090在延迟和性价比上也表现出色,适合大规模部署。
六、实际部署与优化策略
为了充分发挥RTX 4090和RTX 3090在百亿级参数小模型推理中的优势,还需要考虑一些实际的部署和优化策略。这些策略可以帮助最大化GPU的利用率,提高推理效率,并减少总体成本。
1. 精细化批处理策略
批处理大小(Batch Size)的选择对推理性能有显著影响。大批处理通常可以提高GPU利用率,但可能增加延迟。因此,在实际部署时需要根据具体应用的需求调整批处理大小。
实时应用:较小的批处理大小可以降低延迟,适合语音识别、实时翻译等应用。
非实时应用:较大的批处理大小可以提高吞吐量,适合大规模文本分类、图像处理等应用。
2. 混合精度推理
混合精度推理(Mixed Precision Inference)利用FP16和FP32两种精度进行计算,可以显著提高计算速度和减少显存占用。NVIDIA的Tensor Cores在这方面表现尤为出色。
实现方法:通过启用TensorFlow或PyTorch中的混合精度训练和推理功能,即可实现混合精度计算。
效果:在RTX 4090和RTX 3090上,混合精度推理可以提高约1.5-2倍的推理速度,同时减少50%的显存占用。
3. 多GPU并行
对于需要处理巨量数据的任务,多GPU并行是提升性能的有效手段。RTX 4090支持NVLink,可实现更高的带宽和更低的延迟。
数据并行:将数据分片,并行处理相同模型的不同数据部分。
模型并行:将模型分片,并行处理模型的不同部分。
混合并行:结合数据并行和模型并行,以最大限度地利用多GPU的计算能力。
4. 动态批处理和任务调度
在实际应用中,输入数据的大小和复杂度可能会有所不同。采用动态批处理和智能任务调度可以优化GPU的利用率。
动态批处理:根据当前系统负载和输入数据的特性,动态调整批处理大小。
智能任务调度:优先处理低延迟任务,合理分配高计算需求任务,实现资源的最大化利用。
七、结论
综上所述,RTX 4090和RTX 3090在百亿级参数小模型推理中展示了显著的优势。通过具体的数据对比和实际案例分析,我们可以得出以下结论:
计算性能:RTX 4090在计算性能上显著优于RTX 3090,特别是在高并发和大批处理任务中表现尤为突出。
能效表现:RTX 4090虽然功耗较高,但其能效比RTX 3090更优,使其在长时间运行中更具成本效益。
成本效益:与A100相比,RTX 4090和RTX 3090在性能和成本之间提供了一个良好的平衡,特别适合预算有限但需要高性能的应用场景。
通过部署精细化批处理策略、混合精度推理、多GPU并行计算以及动态批处理和任务调度策略,可以进一步优化RTX 4090和RTX 3090的性能,满足多种实际应用的需求。
因此,对于百亿级参数的小模型推理任务,使用RTX 4090和RTX 3090显卡不仅能够提供卓越的性能,还能在能效和成本效益方面带来显著的优势。根据具体需求选择合适的显卡,并结合优化策略,可以在性能、能效和成本之间找到最佳的平衡点,为各种AI应用提供强有力的支持。